Much is being written about data centres these days. Yet with the shrouding of AI over everything has come a fog of information about the design, use and future of data centres. In this series, I briefly introduce data centres and provide the background to understand their future.
This first part explores the diverse applications and services that drive data centre design.
Skipping over history
While the history of computing can help to explain how we arrived at the current design of data centres, it’s a long journey to go from their first origins in 1946 to today’s behemoths. If you’re interested in the history, there’s a brief introduction written by Digital Reality, a Wikipedia article and this article by data centre operator TRG.
Applications & services
To understand data centres, I think you first need to know what problem a data centre is solving. Unfortunately that’s a little bit easier said than done because modern data centres solve numerous different problems. We’ll start with the most basic example and build up.
1. Files - the traditional storage unit of data
Long before we had web apps and REST APIs, we had files. Lots of them. We quickly found we needed better ways to share the data contained in files than printing them on paper or writing them to floppy disks to be passed around. (No, I wasn’t alive to experience the heyday of the floppy disk. Yes, I’ve used floppy disks for actual work. No, it wasn’t full of nostalgic fun.)
To that end, networks of computers were invented. This required solving several challenges which are still being improved upon to this day.
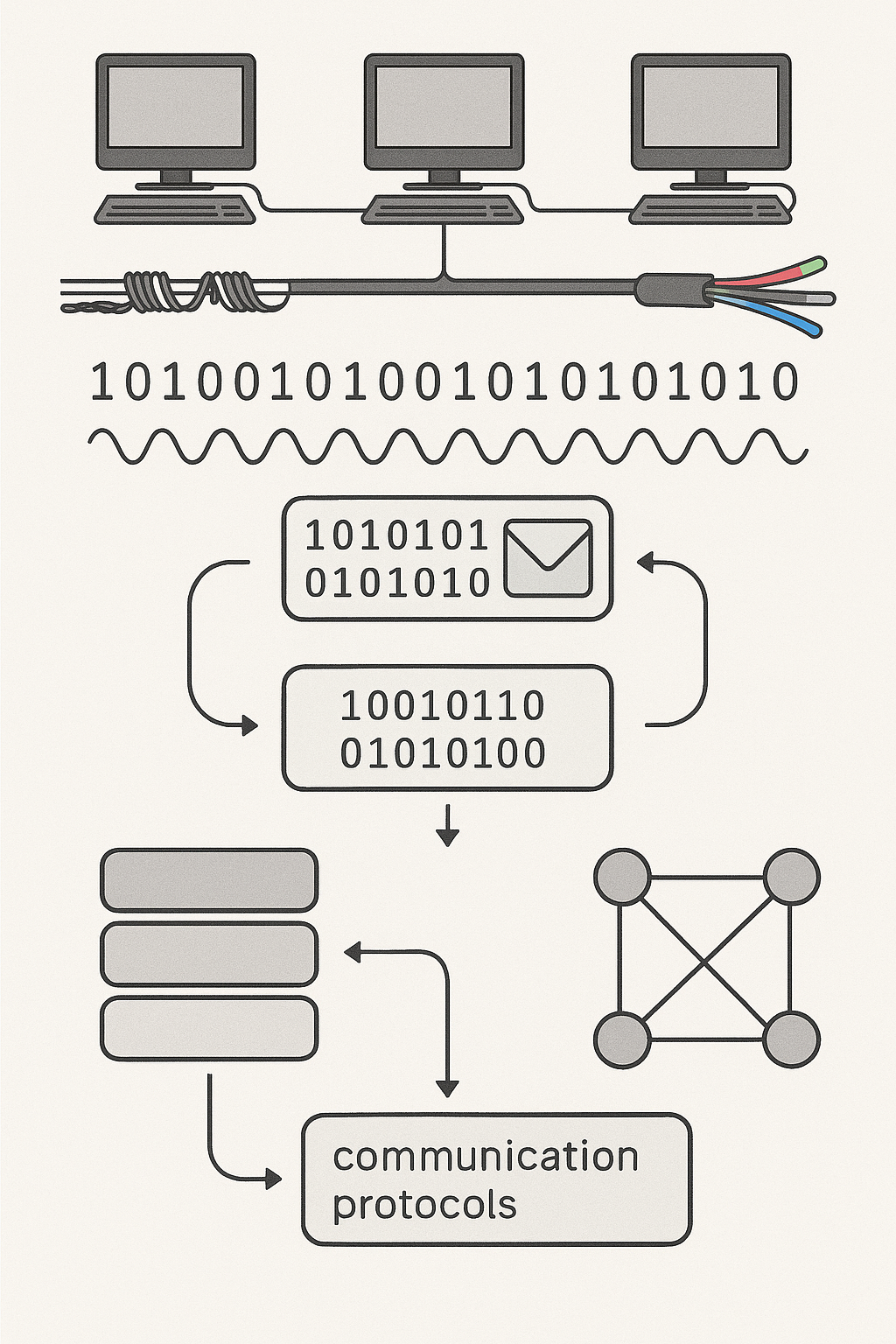
-
Physical connections: Wires and optical fibres running between computers
- It is profound to realise that, except for WiFi connections from your device, there are physically continuous lines from your home to servers all around the world (albeit, with computer boxes in between, that connect different parts of wire or optical fibre together).
- Signalling protocols: The patterns to vary voltages on the wires, or pulses of lights sent down the optical fibres, needed to communicate ‘bits’ (1s and 0s)
- Transmission protocols: Given some data to send, how to transform that into a pattern of 1s and 0s to send over the physical connection.
- Communication protocols: Layered on top of transmission protocols to add more complex communication, things like:
-
Network protocols/layers: The communications that coordinate the
creation, maintenance and closing down of communication channels between
pieces of software on different machines. Also the structure of the network -
routing.
- Routing: Directing information from one computer to another and on to its destination.
- Drivers: The software which drives these various protocols in response to a request by application software.
Having solved the fundamental problem of how to communicate some data from software on one machine to software on another, we were able to solve the problem of sharing files.
Transmitting files from one machine to another is all well and good but it opens up new issues. In particular, how do we share two versions of the same file? How can one user access a file from a machine which is currently switched off? What happens if the hard disk drive in a machine fails? How can all files in a network be backed up? And so on…
Today’s solutions to these problems are known generally as Object Storage (and, in a related use-case, databases). Amazon Web Services’ S3 (“Simple Storage Service”) has become a standard design for this kind of file storage, accessed through APIs rather than traditional file systems. Users don’t see this behind-the-scenes design - most will use some kind of interface, whether that’s a web app like Google Drive, or a file system integration like One Drive on Windows.
S3 is one of the largest services provided by modern data centres. It stores files (“objects” or “blobs”) with extremely high resiliency.
2. Websites
To understand websites in the context of data centres, I’ll draw a useful (if somewhat artificial) distinction: websites serve static content that users download and consume, while apps are interactive systems where users both input and retrieve data. In this model, websites are essentially specialized collections of text files, images, videos, and other media formatted for web browsers.
At first glance, websites might seem like they should simply use the file storage systems described earlier. Indeed, many websites do exactly this - static site hosting on AWS S3 or similar services is a common pattern for simple websites. However, modern websites have evolved far beyond static file delivery.
The key difference lies in dynamic content generation. Even websites that don’t accept user input often change their content over time. News sites pull stories from databases, advertising sites select a new advert to serve on every request, and content delivery networks serve different versions based on geographic location. Two users requesting the same URL might receive entirely different content depending on their location, the time of day, or browsing history - advertising networks like Google’s DoubleClick exemplify this personalization.
This shift from static to dynamic content represents a crucial evolution in data centre architecture. Rather than simply retrieving files from storage, servers must now compute responses in real-time. When a page is requested, the request gets routed by a load balancer to a server capable of executing the necessary logic - whether that’s querying databases, processing templates, or integrating multiple data sources.
It’s worth noting that “server” is simply our term for any computer fulfilling this serving role, regardless of its physical form. However, when we use “server” without qualification, we typically mean machines with substantial processing power and memory capacity designed for this purpose.
This computational requirement introduces workload diversity within data centres. Some servers respond directly to user requests, while others run databases and respond to internal queries from the web servers. This specialization marks the beginning of the complex, heterogeneous computing environments that define modern data centres.
3. Apps
Apps introduce the next level of complexity beyond websites by enabling bidirectional communication between users and servers. While websites primarily deliver content to users, apps allow users to send data back - ranging from simple form submissions containing usernames and passwords to massive file uploads like video content that can be gigabytes in size.
This fundamental shift transforms server requirements dramatically. Servers must now accept incoming data, validate and sanitize user input, and compute results using potentially untrusted data. This introduces numerous new architectural challenges: expanded memory capacity to buffer incoming data, robust security boundaries since user input cannot be trusted, and sophisticated error handling for malformed or malicious requests.
The demand for bidirectional communication also creates entirely new scaling problems. Traditional websites could handle traffic spikes by replicating static content across multiple servers distributed globally - a straightforward horizontal scaling approach. Apps complicate this model significantly. When a user uploads a video to YouTube or TikTok, a specific server must be available to accept, process, and initially store that content. The video then needs sophisticated replication across content delivery networks (CDNs) to make it available to millions of users worldwide with acceptable latency. For TikTok, which prioritizes ultra-low upload latency to keep creators engaged, this requires edge computing infrastructure positioned close to users worldwide.
Geographic distribution becomes critical for user experience, but physical infrastructure ownership everywhere is prohibitively expensive. Request latency is fundamentally constrained by the speed of light - for applications requiring real-time interaction, such as VR experiences that demand maximum latency of 20ms, this creates a maximum practical distance of approximately 350km between user and server when accounting for processing time and transmission delays (the limitation here is the speed of light in a fibre optic cable)!
These geographic constraints helped to drive the emergence of cloud computing and virtualization. Companies need the ability to rent compute capacity on physical machines shared with other organizations, while maintaining the flexibility to scale operations up and down rapidly without physical hardware reconfiguration. Virtual machines (VMs) provide the solution - appearing to software as dedicated physical machines while enabling multiple isolated environments to coexist on shared hardware. VMs are managed by a hypervisor that abstracts the underlying hardware and can be provisioned and destroyed in minutes rather than the days or months required for physical server deployment.
However, virtualization introduces its own challenges, particularly the “noisy neighbour” problem where one virtual machine’s resource consumption can impact the performance of others sharing the same physical hardware. While various mitigation strategies exist, some aspects of this challenge remain unsolved, particularly for workloads requiring consistent, predictable performance.
4. Trading
Our next example takes us in a fundamentally different direction from traditional web services. Trading, particularly high-frequency trading (HFT), requires making rapid decisions using imperfect and incomplete data streams. Success depends not just on algorithmic sophistication, but on maintaining ultra-low latency connections between all servers involved in a trade’s execution.
HFT requires processing massive streams of real-time market data using complex mathematical operations - work that differs entirely from reading files from disk and transmitting them over networks. Servers optimized for web requests, file serving, and database queries are fundamentally unsuited for trading workloads.
Understanding this distinction illuminates a key trend in modern data centre design: workload specialization driving hardware heterogeneity.
Consider the computational flow of rendering a web page. A server receives a small request, parses it character-by-character to identify structure and extract information like the requested URL, then dispatches internal requests to other servers for files or database responses. The server doesn’t sit idle waiting for these responses - it context-switches to handle additional incoming requests. When internal responses return, it resumes the original request, generates the web page, and transmits the final response to the user. This request-response pattern demands three key capabilities: substantial RAM memory to buffer requests and responses, high-bandwidth networks for data movement, and CPUs optimized for memory-intensive operations, highly-branching code execution, and maintaining numerous parallel threads simultaneously.
Trading servers require entirely different capabilities. Rather than discrete request-response cycles, trading operates as continuous data streams. Incoming market data flows through algorithmic processing pipelines that integrate information into specialized time-series databases. Quantitative trading algorithms then scan across this temporal data, often processing ranges in parallel blocks before aggregating results for decision-making algorithms.
This streaming architecture requires CPUs specialized for: consuming single-use data efficiently, streaming from external time-series sources, performing massively parallel mathematical operations across data points simultaneously, and aggregating distributed computations into unified results. In practice, this necessitates processors with vector operations, shallow cache hierarchies, and extremely low-latency network connections.
While general-purpose CPUs have dominated computing for decades, trading firms have increasingly adopted FPGAs (Field-Programmable Gate Arrays) and custom ASICs (Application-Specific Integrated Circuits) to achieve dramatically superior performance for their specialized workloads. Companies like Jane Street and Citadel Securities have invested heavily in custom hardware and co-location facilities to minimize latency. This trend represents a broader movement away from one-size-fits-all computing toward purpose-built hardware architectures.
5. Gaming
Real-time multiplayer gaming represents another fascinating departure from traditional web services, with titles like Fortnite, Counter-Strike, Dota 2, and Rocket League creating entirely unique demands on data centre infrastructure. While the computational complexity of game logic itself remains relatively modest - tracking player positions, processing simple physics calculations, and validating moves - the challenge lies in managing thousands of tiny data packets flowing between server and clients every second.
This creates a fundamentally different scaling challenge than the applications we’ve examined so far. Gaming servers must maintain extremely low latency while simultaneously handling dozens or hundreds of concurrent players. The data volume per player is remarkably small, often just a few bytes containing position updates or action commands, but the timing requirements are unforgiving. A delay of even 50 milliseconds can render competitive games unplayable, creating what players experience as “lag”, “rubber banding”, missed hits and score incoherence. Since many players use some kind of real-time communication with friends (e.g. Discord voice chats), these irregularities are very noticeable.
The network packet handling requirements for gaming directly conflict with standard data centre optimization strategies. Traditional web services benefit from packet coalescing - bundling multiple small data transmissions into larger, more efficient bursts that maximize network throughput. Video streaming services exemplify this approach, as user devices can buffer content and slight delays remain invisible to viewers.
Gaming demands the exact opposite: immediate transmission of every individual packet, regardless of efficiency concerns. Delaying a player’s movement command while waiting to bundle it with other data creates the stuttering, unresponsive gameplay that destroys user experience. This requirement puts gaming servers at odds with standard network security measures, since flooding networks with millions of small packets is a common Denial of Service (DoS) attack pattern.
Data centre operators must therefore implement specialized packet prioritization policies and, in some cases, dedicate specific physical network infrastructure to gaming workloads. Some gaming companies require servers connected to dedicated routers and switches, isolated from general web traffic, to ensure their packet handling requirements can be met without triggering security systems designed to block malicious traffic patterns.
The challenge becomes even more complex when gaming companies attempt to leverage public cloud infrastructure rather than operating dedicated gaming-specific data centres. Major cloud providers optimize their networks for the high-throughput, bursty traffic patterns of web services and data processing workloads. Adapting these networks for gaming’s continuous, low-latency requirements has proven a significant stumbling block for many game hosting operations, though specialized gaming-focused cloud services like AWS GameLift and Google Cloud Game Servers are beginning to address these constraints. Companies like Riot Games have built their own global network infrastructure to ensure consistent performance for League of Legends players worldwide.
6. Number crunching
Raw computational workloads represent another distinct category of data centre applications, encompassing everything from weather prediction models to genomics research to sports analytics. While the umbrella term “number crunching” might suggest similarity, these applications actually impose dramatically different requirements on server infrastructure.
Consider the computational patterns involved. Weather forecasting requires processing massive datasets where each geographic grid point can be computed independently before results are aggregated into global models. The European Centre for Medium-Range Weather Forecasts (ECMWF) operates some of the world’s most powerful supercomputers specifically for this highly parallel workload - computational problems that can be divided into many independent tasks. Similarly, Netflix uses massive parallel computing to process video encoding, creating multiple quality versions of each title for different device capabilities and network conditions.
Genomics research presents an entirely different challenge. DNA sequencing analysis often requires processing long chains of calculations where each step depends on the results of previous computations. Rather than independent parallel processing, these workloads demand sequential computational pipelines with substantial intermediate data storage and high-speed data movement between processing stages.
Sports analytics illustrates yet another pattern: processing continuous streams of real-time data to generate insights during live events. This requires servers optimized for streaming computation with minimal buffering delays, as companies like Second Spectrum demonstrate in their real-time basketball analytics platforms. Amazon’s statistical analysis for NFL games and ESPN’s real-time win probability calculations require similar streaming computational architectures.
These divergent computational patterns drive fundamentally different server requirements. Weather forecasting benefits from processors with massive numbers of cores operating in parallel, substantial high-bandwidth memory to hold large datasets, and relatively modest storage requirements. Genomics research may demand processors optimized for sequential throughput, enormous amounts of both memory and storage, and specialized interconnects for coordinating complex computational pipelines. Sports analytics requires processors optimized for streaming workloads with minimal latency, moderate memory capacity, but sophisticated network interfaces for consuming continuous data feeds.
The heterogeneity of computational workloads has driven data centres toward increasingly specialized hardware architectures, with some operators dedicating entire facilities to specific types of number crunching applications.
7. AI
My final example in this section explores AI - specifically Large Language Models (LLMs) that now dominate through Generative AI applications. For hardware vendors, AI has been nothing short of transformational. The reason becomes clear when you examine what these systems demand: AI workloads push virtually every aspect of computing to its limits, simultaneously.
Consider the computational requirements of a single LLM inference request. When you submit a prompt to ChatGPT or Claude, the server must process your input through massive neural networks containing billions of parameters. This requires enormous amounts of high-speed memory to hold the model weights, sophisticated parallel processing capabilities to perform matrix multiplications across thousands of compute units simultaneously, and substantial throughput to handle the cascading calculations that generate each token of the response.
Unlike our previous examples, AI workloads combine the most demanding characteristics from every category we’ve discussed. They require the massive parallel computation of number crunching applications, the low-latency responsiveness expected from interactive apps, the high-throughput data movement of file storage systems, and the complex user session management of traditional web services. A single AI inference request might involve terabytes of parameter data flowing through specialized processors, followed by careful orchestration to serialize millions of parallel computations into a coherent text response.
The storage requirements alone are staggering. GPT-4’s parameter count is estimated in the hundreds of billions, requiring hundreds of gigabytes just to store the model weights. Training these models demands even more extreme resources - Facebook’s LLaMA 2 training reportedly required millions of GPU hours, while Google’s PaLM training consumed computational resources equivalent to running thousands of high-end servers continuously for months.
Network demands compound these challenges further. Users upload everything from simple text prompts to images, documents, and increasingly large context windows. The responses flow back as continuous streams of generated tokens, creating bidirectional traffic patterns that stress both upload and download infrastructure simultaneously. Meanwhile, the underlying systems must handle traditional application concerns: parsing user requests, managing authentication and rate limiting, coordinating between multiple specialized servers, and maintaining session state across potentially lengthy conversations.
This convergence of extreme requirements helps explain why Generative LLMs only became viable in the last decade. The cloud data centre architecture - with its ability to disaggregate massive computations across heterogeneous server types connected by high-speed networks - provided the essential foundation. Modern data centres can orchestrate specialized GPU clusters for model inference, high-memory servers for parameter storage, traditional CPUs for request handling, and sophisticated networking infrastructure to coordinate these disparate components into unified AI services using multi-tenant architectures that efficiently share resources among multiple customers.
The hardware implications extend beyond individual servers to entire facility design. AI workloads generate exceptional heat loads, requiring enhanced cooling systems. They demand reliable power delivery at unprecedented scales - NVIDIA’s H100 GPU consumes up to 700 watts per chip, and AI servers often contain eight or more such processors. The result is that AI-optimized data centres represent a fundamental shift in infrastructure design, optimized for power density and cooling capacity that would have been unthinkable just a few years ago. Companies like Microsoft and Google have built specialized AI infrastructure, while OpenAI partnered with Microsoft to access the massive computational resources required for training and serving models like GPT-4.
Coming Next
In Part 2 of this series, we’ll dive into the physical structure of data centres - exploring how these diverse application requirements translate into actual hardware configurations, facility design, and the complex systems that keep everything running.
Series Navigation
- Part 1: Understanding Applications and Services (this post)
- Part 2: Physical Architecture of a Single Data Centre
- Part 3: Virtual Architecture of a Single Data Centre
- Part 4: Spanning Multiple Data Centres
- Part 5: Business Models and Economics
- Part 6: Evaluation and Future Trends
Glossary
A set of protocols and tools that allow different software applications to communicate with each other. APIs define the methods and data formats applications can use to interact with external services or systems.
REST APIs are widely used in web services, while object storage systems like S3 provide APIs for programmatic file access without traditional file system interfaces.
Back More...Custom-designed computer chips optimized for specific tasks, offering superior performance but limited flexibility compared to general-purpose processors. ASICs are created for a single application and cannot be reprogrammed, making them extremely efficient but costly to develop.
Trading firms like Citadel Securities and tech companies use ASICs for high-frequency trading algorithms and cryptocurrency mining, where the performance gains justify the development costs.
Back More...A distributed network of servers positioned globally to deliver content to users from locations geographically closest to them, reducing latency and improving performance. CDNs cache static content like images, videos, and web pages across multiple geographic locations.
Major CDN providers include Cloudflare, Amazon CloudFront, and Akamai. Netflix uses extensive CDN infrastructure to stream videos with minimal buffering worldwide.
Back More...The delivery of computing services including servers, storage, databases, networking, and software over the internet, enabling on-demand resource provisioning and pay-as-you-use pricing models.
Major cloud providers like AWS, Microsoft Azure, and Google Cloud operate massive data center networks to provide these services with global reach and high availability.
Back More...A data center service where customers place their own servers and networking equipment in a shared facility, benefiting from professional-grade power, cooling, and network connectivity without operating their own data center.
High-frequency trading firms use co-location services near stock exchanges to minimize network latency, often measuring advantages in microseconds.
Back More...Denial of Service attacks that attempt to overwhelm servers or networks with traffic, making services unavailable to legitimate users. DDoS (Distributed Denial of Service) attacks use multiple compromised systems to amplify the attack volume.
Common attack vectors include UDP floods, SYN floods, and application-layer attacks.
Back More...Computing infrastructure positioned close to end users to reduce latency and bandwidth usage by processing data locally rather than in distant centralized data centers.
Applications like autonomous vehicles, augmented reality, and real-time gaming require edge computing to meet strict latency requirements that centralized cloud computing cannot satisfy.
Back More...High-speed data transmission medium using light pulses through glass or plastic fibres, enabling much higher bandwidth and longer distances than traditional copper cables.
Data centers rely on fibre optic connections for inter-facility communication, with light travelling at approximately 200,000 km/s in fibre, which fundamentally constrains network latency.
Back More...Programmable computer chips that can be reconfigured for specific tasks after manufacturing, offering a middle ground between flexible CPUs and specialized ASICs. FPGAs contain configurable logic blocks that can be programmed to implement custom digital circuits.
High-frequency trading firms use FPGAs for ultra-low latency processing, while cloud providers like AWS offer FPGA instances for specialized workloads requiring custom hardware acceleration.
Back More...Specialized processors originally designed for graphics rendering, now widely used for parallel computing tasks including AI and machine learning. GPUs excel at performing many simple calculations simultaneously, making them ideal for matrix operations in neural networks.
NVIDIA's H100 and A100 GPUs power most modern AI training and inference, while gaming GPUs from NVIDIA and AMD serve both entertainment and computational workloads.
Back More...Automated trading strategies that execute large numbers of transactions in fractions of a second, requiring extremely low-latency infrastructure. HFT systems analyze market data and execute trades in microseconds, often using co-location services near stock exchanges.
Firms like Jane Street and Two Sigma invest heavily in custom hardware, direct market feeds, and geographic proximity to exchanges to achieve competitive advantages measured in nanoseconds.
Back More...The foundation protocol of web communication, defining how web browsers and servers exchange information. HTTP uses a request-response model where clients send requests and servers provide responses.
Modern web applications layer complex functionality on top of HTTP, while newer protocols like HTTP/2 and HTTP/3 improve performance for dynamic content delivery.
Back More...Software that creates and manages virtual machines by abstracting physical hardware resources and allocating them to multiple isolated virtual environments running on the same physical server.
Type 1 hypervisors like VMware vSphere run directly on hardware, while Type 2 hypervisors like VirtualBox run on top of existing operating systems.
Back More...The time delay between a request being made and a response being received, typically measured in milliseconds for network communications. Latency is constrained by the speed of light in fibre optic cables (~200,000 km/s) and processing delays.
Real-time applications like VR require under 20ms latency, while web browsing can tolerate 100-200ms. Gaming applications typically need under 50ms to feel responsive.
Back More...AI models trained on vast amounts of text data to understand and generate human-like text, such as GPT-4 or Claude. LLMs use transformer architectures with billions of parameters to process and generate text by predicting the next token in a sequence.
Modern LLMs require massive computational resources for training and inference, driving demand for specialized AI data centers with thousands of GPUs.
Back More...Network device or software that distributes incoming requests across multiple servers to prevent any single server from becoming overwhelmed, improving reliability and performance.
Cloud providers offer load balancing services like AWS Elastic Load Balancer and Google Cloud Load Balancing to automatically distribute traffic across server fleets.
Back More...Architecture where a single instance of software serves multiple customers (tenants) while keeping their data and configurations isolated from each other.
Cloud providers use multi-tenancy to efficiently share physical infrastructure among thousands of customers while maintaining security and performance isolation.
Back More...In virtualized environments, when one virtual machine's resource usage negatively impacts the performance of other VMs sharing the same physical hardware. This can affect CPU, memory, storage I/O, and network bandwidth availability.
Cloud providers use various isolation techniques, but the problem persists for workloads requiring consistent performance. Some applications require dedicated hardware to avoid this issue entirely.
Back More...A data storage architecture that manages data as objects (files) with metadata, designed for scalability and durability across distributed systems. Each object includes the data, metadata, and a unique identifier, accessed via REST APIs rather than traditional file systems.
Object storage excels at storing unstructured data like documents, images, and videos with built-in redundancy and geographic distribution.
Back More...A formatted unit of data carried over a network, containing both payload data and routing information. Networks break larger messages into packets for efficient transmission and reassemble them at the destination.
Gaming applications require immediate transmission of small packets rather than bundling them for efficiency, creating unique challenges for data center network design.
Back More...An architectural style for designing web APIs that uses standard HTTP methods (GET, POST, PUT, DELETE) to interact with resources identified by URLs.
Most cloud services including AWS S3, Google Cloud, and Azure expose REST APIs, making them accessible from any programming language or platform that supports HTTP.
Back More...Amazon's object storage service that has become the de facto standard architecture for cloud file storage. S3 provides 99.999999999% (11 9's) durability through automatic replication across multiple data centers.
S3's API design has been widely adopted, with compatible services offered by Google Cloud Storage, Microsoft Azure Blob Storage, and many other providers.
Back More...A system's ability to handle increasing amounts of work by adding resources. Horizontal scaling adds more servers, while vertical scaling increases the power of existing servers.
Modern web applications achieve scalability through microservices architectures, load balancing, and cloud-native designs that can automatically provision resources based on demand.
Back More...A computer designed to provide services, resources, or data to other computers (clients) over a network. Servers typically have enhanced processing power, memory, and reliability compared to desktop computers.
Data centers contain thousands of servers optimized for different workloads, from web serving and database operations to AI training and high-frequency trading.
Back More...A network protocol that ensures reliable, ordered delivery of data between applications over networks. TCP handles packet ordering, error detection and correction, flow control, and congestion management.
TCP is connection-oriented and prioritizes reliability over speed, making it ideal for web browsing, file transfers, and email but less suitable for real-time gaming or video streaming.
Back More...The amount of data successfully transferred over a communication channel in a given period, typically measured in bits per second (bps) or packets per second.
While latency measures speed of individual communications, throughput measures the volume capacity of a system, both of which are critical for different data center applications.
Back More...Software that creates isolated computing environments on shared physical hardware, allowing multiple operating systems to run simultaneously on one machine. VMs include virtual CPU, memory, storage, and network interfaces managed by a hypervisor.
Cloud providers like AWS EC2, Google Compute Engine, and Azure Virtual Machines offer on-demand VM provisioning, enabling flexible resource scaling.
Back More...Technology that creates virtual versions of computing resources (servers, storage, networks), enabling better resource utilization and flexibility. Virtualization abstracts hardware resources, allowing multiple workloads to share physical infrastructure efficiently.
Modern data centers rely heavily on virtualization for multi-tenancy, resource optimization, and rapid provisioning of computing resources.
Back More...